
目次
GPT-4oの実力はいかに?
ChatGPTの最新エンジンであるGPT-4oは、テキスト、音声、画像といったさまざまな情報を処理できるマルチモーダルモデルです。特に画像処理能力が強化され、日本語の読み取り精度も大幅に向上していると聞きます。
そこで今回は、GPT-4oのOCR機能を検証してみたいと思います。
そもそもOCRって何?と思う方もいるでしょう。
簡単に言うと、画像上の文字をデジタルテキストに変換する技術です。
でも実際のところ、どのくらいの精度で読み取れるのか気になりますよね?
今回は、いくつかの画像を用意しました。
簡単なものから始めて、徐々に難易度を上げていきながら、GPT-4oがどこまで対応できるかを試してみたいと思います。
果たしてGPT-4oはすべての文字を正確に読み取れるのか?
いざ実験開始です!
OCR技術の基本をおさらい
まずはOCR技術について簡単におさらいしましょう。
OCRとは、「Optical Character Recognition」の略で、日本語では「光学式文字認識」と言います。
OCRは、スキャンされた文書や画像に含まれる文字を識別し、機械で読み取れるテキストに変換するプロセスです。
歴史的には、OCRは手書き文字を機械で読み取る技術から始まりましたが、現在では印刷されたテキストやデジタル画像からの文字認識にも広く使用されています。
GPT-4oのOCR機能について
GPT-4oは、画像認識とテキスト抽出の両方に対応した最新のAIモデルです。
通常のOCR機能に加えて、複雑なレイアウトや手書き文字を認識することもできます。
それでは、実際にどの程度の精度で文字を読み取れるかを見てみましょう。
検証してみよう!
検証手順は、各レベルの画像をGPT-4oに添付し「これを文字起こしして」というプロンプトを投げることにより実行。
出力結果を調査しました。
難易度の低い順にLevel1~Maxまで8つの検証結果を順番に紹介していきます。
文章を書くすべての人におすすめする日本語用字用語集の決定版。
その中の「外国語地名一覧」の1ページ(P.706)を読み取ってみました。
文字種はカタカナ・アルファベット・漢字と網羅されています。
紙面は割ときれいに撮影したものをChatGPTに投げてみました。


さすが、高い精度で認識できましたが、行頭の◎と○が結構適当でした。
文字の間違いは「キラウエア」→「キラウェア」(「エ」が小文字に)と「〈山〉」が「(山)」(山カッコが丸カッコに)の2カ所でした。
これはOCRあるあるですね。
見た目が似ているものに置き換わることはよくあります。
ほかには、
・「り」(ひらがな)→「リ」(カタカナ)
・「口」(漢字のくち)→「ロ」(カタカナのろ)
・「才」(漢字のさい)→「オ」(カタカナのオ)などなど・・・
見た目が似ている文字については、結構見落としがちなので注意が必要ですね!
文学史上に大きな足跡を残した近代詩人・中原中也。
その中でも最も有名な「ゆあーん ゆよーん ゆやゆよん」でおなじみの詩を読み取ってみました。
縦書きで、ところどころにルビもあって、難しい漢字もあります。果たして・・・。


ルビは見事にスルーされていますね。
間違いは結構ありました。画像の赤枠です。
「一と殷盛り」→「一盛上り」…ひともりあがり? 意味は近いかな?
「安値い」→「安い」…読めてはいますよね。
「観客様はみな鰯」→「観客は皆鰐」…観客はみんなワニって!? コワい・・・。
あとは、矢印箇所で1行抜けていたり、「哄笑の」や「闇の中へと投げられた 諸声 諸声」はないものが追加されています。
あと残念だったのが「ゆやゆよん」のところ。
いちばんおいしいところを間違えちゃってますね。
「ゆやゆよーん」と伸ばしたくなるのはなんとなくわかるけど・・・。
大正時代末期から昭和時代初期にかけて活躍した日本の童謡詩人・金子みすゞ。
こちらもおなじみの詩をわたしが手書きしたもので読み取ってみました。
手書き文字に挑戦。でもちょっと上手く書きすぎたかな?


100点!
ちょっと上手く書きすぎちゃいましたね・・・。
詩の形(改行位置)は再現できていませんが、これぐらいの手書きはお手の物ですね。
独特な「書体と詩」で多くの人々に感動と勇気を与えた書家・相田みつを。
こちらも有名な詩を読み取ってみます。先ほどの私の手書きより難易度は上がってますよね?

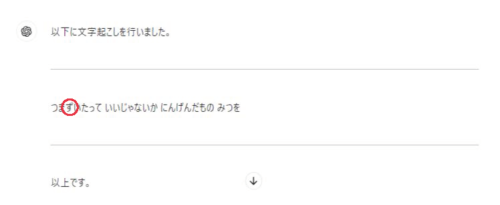
「つまづいたって」が「つまずいたって」になっています。
「つまづく」は歴史的仮名遣いで、現代仮名遣いの文であれば、「つまずく」が基本です。
Level1で紹介した『記者ハンドブック』でも「つまずく」と載っています。
これはGPT-4oが現代仮名遣いに直したってことでしょうか?
でも、そこは原文イキにしてほしかった。
「ニセみつお(わたし)」がわざと間違えてみましたが、どうでしょうか?

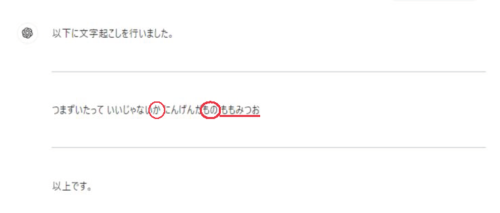
あれ?
「いいじゃないか」、「にんげんだもの」って、これはGPT-4oさん、原文を知ってますね?
「もも」を「もの」って直してほしかったのに、作「ももみつお」になっちゃってます。
中原中也の初期の代表作『朝の歌』。しかも直筆原稿!

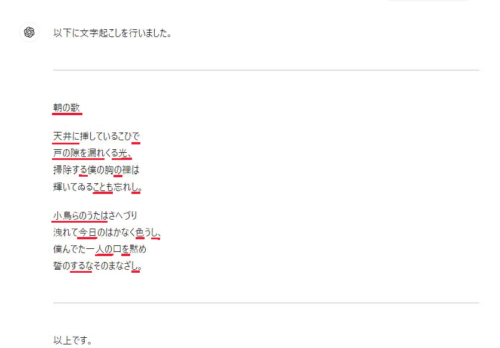
う~~ん、やっぱり直筆原稿は難易度が高すぎたか?
原稿用紙の右半分しか読み取っていないみたいですね。
でも、ところどころ合ってるんです(赤下線部)。
読めた文字をAIで埋め合わせた結果、こんな文章を作っちゃったって感じですかね?
まだLevel6なのに!
画像の解像度の問題なのか?
もっときれいな画像だったらいけたのか?
日本文学に特異な世界を切り開いた詩人・童話作家の宮沢賢治。
有名な詩のひとつ『雨ニモマケズ』が書かれた宮沢賢治直筆の手帳。

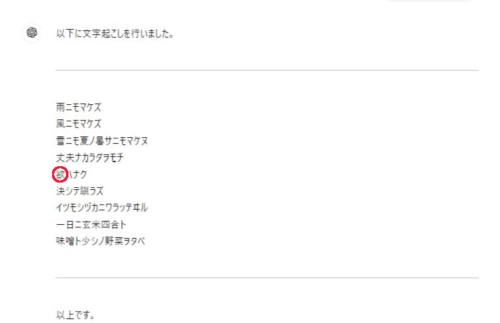
Level6より難しいと思ったけど、こっちのほうがイケました!
結構クセのある文字なのに、ほぼ正確に認識できました。
間違いは「慾」が「欲」になっているだけでした。
これも有名すぎてGPT-4oが知っていた可能性もありますね。
坂本龍馬の手書きの手紙。「日本を今一度せんたくいたし申候事ニいたすべく・・・」という有名なフレーズ。
Levelマックスです! 果たして・・・。

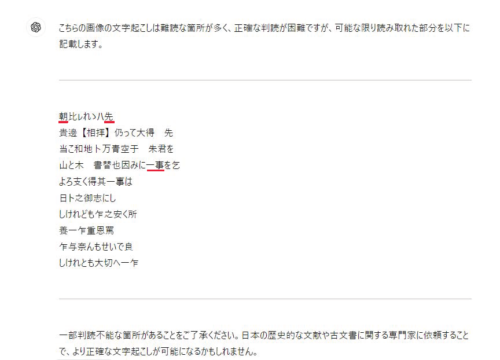
「そりゃあそうだ」って結果になりました。
わたしでも読めませんよ!
最初の「朝」など、ところどころ読めている漢字もありましたが、さすがに無理でした。
難易度の高いものは、途中でギブアップする傾向にあるようです。
最終LevelMaxはこのような結果になりました!
検証結果はまさかの・・・?
GPT-4oのOCR機能を検証した結果をまとめてみました。
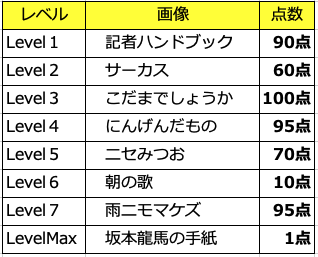
点数を付けてみるとこんな感じでしょうか?
この結果を見ると、縦書きは苦手そうですね。詩という独特の形態もあるのかもしれません。
『朝の歌』と『坂本龍馬の手紙』はしょうがないですよね。
それでも何とか読み取ろうとした努力は素晴らしいのではないでしょうか?
『にんげんだもの』や、『ニセみつお』『こだまでしょうか』のわたしの手書き文字は比較的読み取れました。
『雨ニモマケズ』が健闘しました! カタカナは比較的読み取りやすいのかもしれません。
ここで検証したものはあくまで一例ですので、画像の解像度や生成AIによって結果が異なる可能性があります。

OCRはいろいろな用途に使える!?
今回の検証でわかったように、GPT-4oのOCR機能は日常的な用途には十分な性能を持ち、紙媒体の情報を正確にデジタルテキストに変換できることがわかりました。
細かい文字が多いページでも高精度で認識できることから、専門的な文書や技術書のデジタル化にも役立ちそうです。
崩し字や特定の書体については今後のアップデートに期待ですね。
自分の日記やノート、メモなんかをデジタル化するのもいいのではないでしょうか。
なくしてしまう前にデジタル化しちゃいましょう!
また、この技術は、以下のようなさまざまな用途に応用できるのではないでしょうか。
歴史文書のデジタル化:貴重な歴史的文書をデジタル化することで、保存や閲覧・検索が容易になります。
教育分野:教師や学生が手書きノートをデジタル化して共有したり、学習資料を簡単にテキスト化したりできます。
さらに、AI技術の進展に伴い、以下のような新しい可能性も期待できます。
高度な文字認識::崩し字や特殊な書体に対する認識精度の向上、特に歴史的文書や芸術作品のデジタルアーカイブ化における貢献。
音声認識との統合: OCR技術と音声認識技術を統合し、視覚障害者向けのドキュメント読み上げアプリケーションの開発。
今回読み取ることができなかったLevelMaxも、近いうちに読み取れる日がくると信じています!
GPT-4oのOCR機能は多くの場面で役立つ実用的なツールです!
みなさんもぜひ、いろんなものを読み取らせてデジタル化してみましょう!
最後に校正だけは忘れずに!
正しくデジタル化しましょう!

